背景
由于单机存储容量、连接数、处理能力有限,当超过一定上限后,数据库会遭遇性能瓶颈,即使优化索引,很多操作的性能仍下降严重。切分 (Sharding) 的目的就在于减少数据库的负担,缩短查询时间。
根据切分类型,可以分为两种方式:垂直切分和水平切分。
分库分表
垂直切分
① 垂直分库
概念:根据业务耦合性,将关联度低的不同表存储在不同的数据库。与”微服务治理”的做法相似,每个微服务使用单独的一个数据库。
结果:
- 每个库的结构、数据都不一样。
- 所有库的并集是全量数据。
场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。

② 垂直分表
概念:某个表字段较多,以列为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
结果:
- 每个表的结构、数据都不一样;
- 所有表的并集是全量数据;
场景:表字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读 IO,产生 IO 瓶颈。
分析:拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用 join,因为 join 不仅会增加CPU 负担并且会将两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务 service 层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。

③ 优缺点
优点:
- 解决业务系统层面的耦合,业务清晰。
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等。
缺点:
- 部分表无法 join,只能通过接口聚合方式解决,提升了开发的复杂度。
- 分布式事务处理复杂。
- 依然存在单表数据量过大的问题(需要水平切分)。
水平拆分
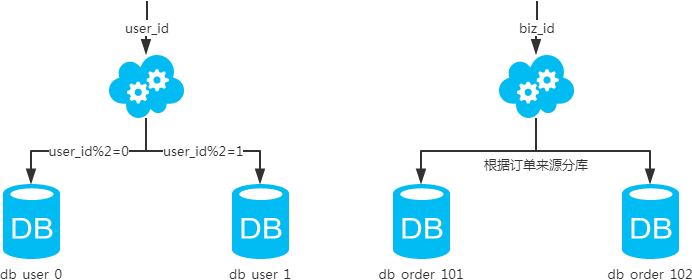
① 水平分库
概念:当一个应用数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。以字段为依据,按照一定策略(hash、range 等),将一个库中的数据拆分到多个库中。
结果:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
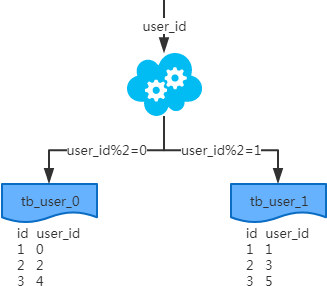
② 水平分表
概念:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
结果:
- 每个表的结构都一样;
- 每个表的数据都不一样,没有交集;
- 所有表的并集是全量数据;
场景:解决了单一表数据量过大的问题。
分析:表的数据量少了,单次 SQL 执行效率高,自然减轻了 CPU 的负担。
③ 优缺点
优点:
- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力。
- 应用端改造较小,不需要拆分业务模块。
缺点:
- 跨库的 join 关联查询性能较差。
- 数据多次扩展难度和维护量极大。
几种典型的数据水平分片规则:
根据数值范围:按照时间区间或 ID 区间切分,例如:按日期将不同月甚至是日的数据分散到不同的库表中,将 userId 为 1
9999 的记录分到第一个库或表,1000020000 的分到第二个库或表。优点:扩容简单
缺点:请求量分布不均匀,导致服务器利用率不平衡
根据数值取模:一般采用 hash 取模 mod 的切分方式,例如:将 Customer 表根据 cusno 字段切分到 4 个库中,余数为 0 的放到第一个库,余数为 1 的放到第二个库。
优点:数据量和请求量分布均匀
缺点:扩容麻烦,需要考虑对数据进行平滑的迁移
分库分表带来的问题
分库分表能有效的环节单机和单库带来的性能瓶颈和压力,突破网络 IO、硬件资源、连接数的瓶颈,同时也带来了一些问题。
事务一致性问题:往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。
跨节点关联查询 join 问题:考虑到性能,尽量避免使用 join 查询,一般通过字段冗余反范式设计、数据组装等方法。
跨节点分页、排序、函数问题:需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。
全局主键避重问题:由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库自生成的 ID 无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。一些常见的主键生成策略:
工具中间件
实践
原则
- 原则 0:能不分就不分。
- 原则 1:数据量太大,正常的运维影响正常的业务访问。
- 原则 2:表设计不合理,需要对某些字段进行垂直拆分。
- 原则 3:某些数据表出现了无穷增长的情况。
- 原则 4:安全性和可用性的考虑。
- 原则 5:业务耦合性考虑。
总结
① 水平拆分和垂直拆分都是降低数据量大小,提升数据库性能的常见手段。
② 流量大数据量大时,数据访问要有 service 层,并且 service 层不要通过 join 来获取主表和扩展表的属性。
③ 垂直拆分的依据,尽量把长度较短,访问频率较高的属性放在主表里。