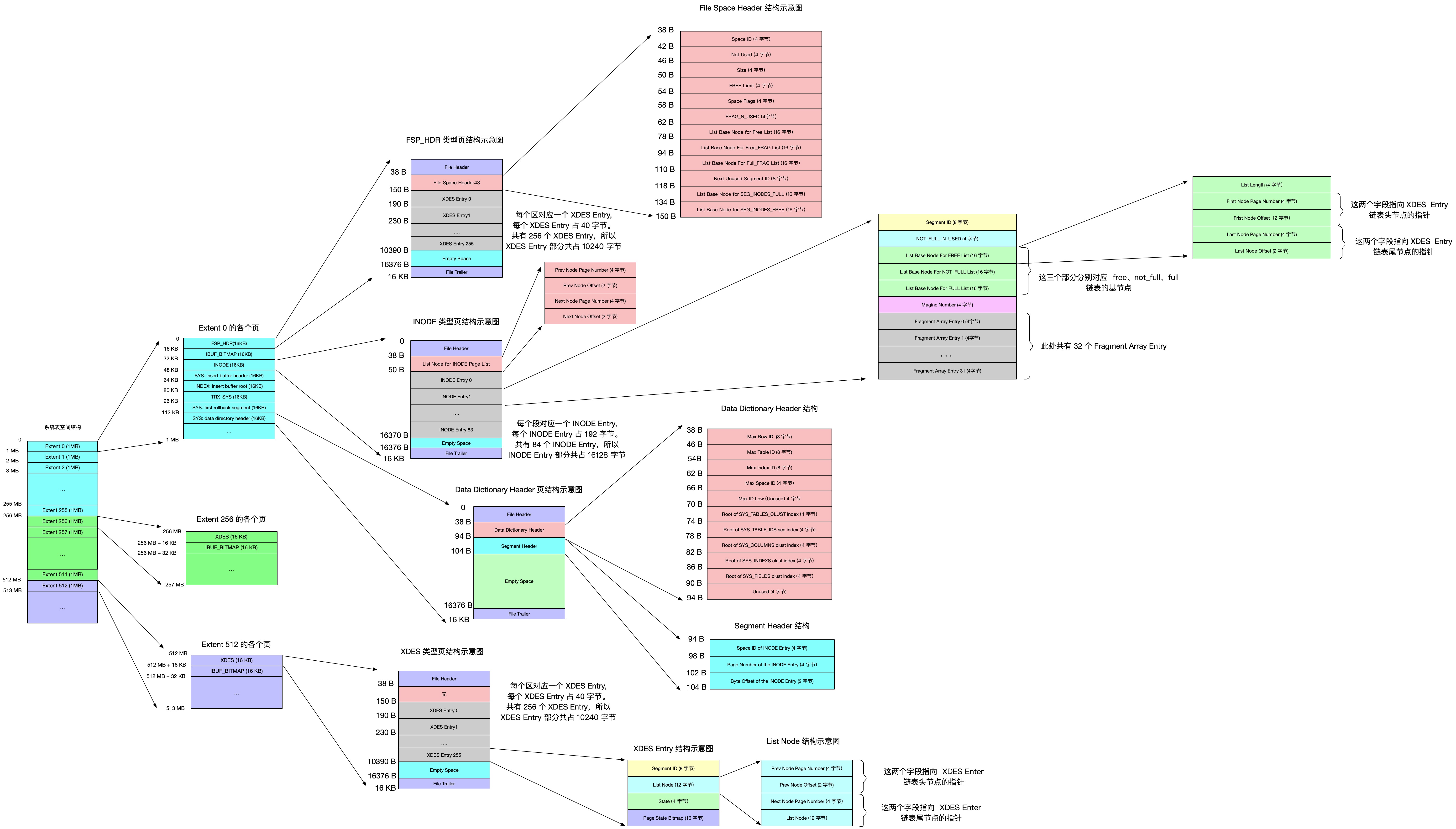
简介
逻辑存储结构
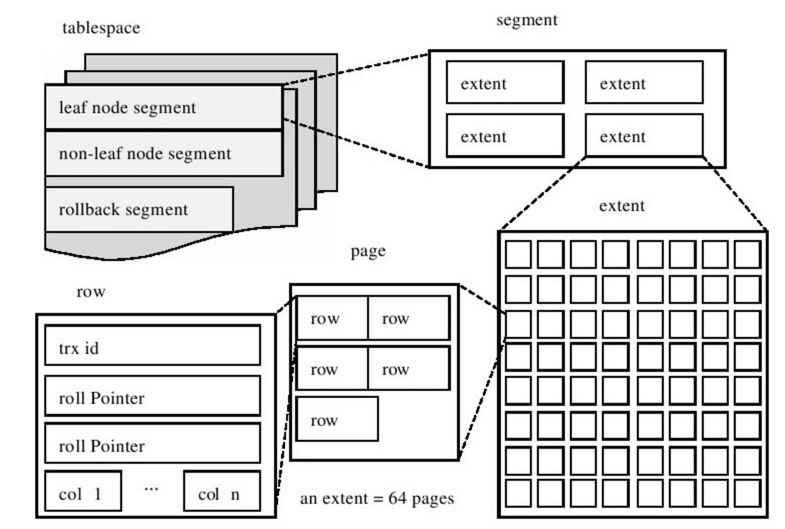
从 InnoDB 存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在同一个空间中,称为 表空间(tablespace)。表空间又由 段(segment)、区(extent)、页(page)组成。
表空间
表空间可以看作是 InnoDB 存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。
共享表空间:ibdata1
undo log、插入缓冲索引页、系统事务信息、二次写缓冲(Double write buffer)等
独立表空间:表名.ibd
数据、索引、插入缓冲 Bitmap 页
段
表空间是由各个段组成,常见的段有数据段、索引段、回滚段等。InnoDB 存储引擎表是索引组织的,因此数据即索引,索引即数据。那么数据段即为 B+ 树的叶子节点,索引段即为 B+ 树的非索引节点。
区
区是由连续页组成的空间,在任何情况下每个区的大小都是 1MB。为了保证区中页的连续性,InnoDB 存储引擎一次从磁盘申请 4~5 个区。在默认情况下,InnoDB 存储引擎页的大小是 16KB,即一个区中一共有 64 个连续的页。
InnoDB 1.2.x 版本新增了参数 innodb_page_size,通过该参数可以将默认页的大小进行调整,但不论页的大小怎么变化,区的大小总是为 1M。
页
页是 InnoDB 磁盘管理的最小单位。在 InnoDB 存储引擎中,默认每个页的大小为 16KB,常见的页类型有:
- 数据页(B-tree Node)
- undo 页(Undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction System Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed Blob Page)
- 压缩的二进制大对象页(compressed Blob Page)
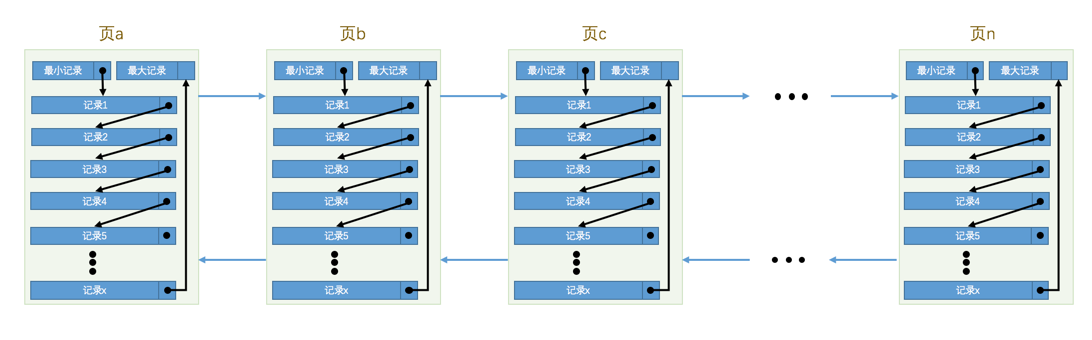
InnoDB 各个数据页可以组成一个 双向链表,而每个数据页中的记录会按照主键值从小到大的顺序组成一个 单向链表,每个数据页都会为存储在它里边儿的记录生成一个 页目录,在通过主键查找某条记录的时候可以在 页目录 中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
行
InnoDB 存储引擎是面向列(row-oriented)的,也就是说数据是按行进行存储的。
行记录格式
InnoDB 存储引擎提供了 4 种不同类型的行格式,分别是 Compact、Redundant、Dynamic 和 Compressed 行格式来存放行记录数据,通过 Row_format 属性可以查询到表使用的行记录结构类型。
1 | mysql> show table status like 'employees'\G |
1 | CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称 |
Compact 行记录格式

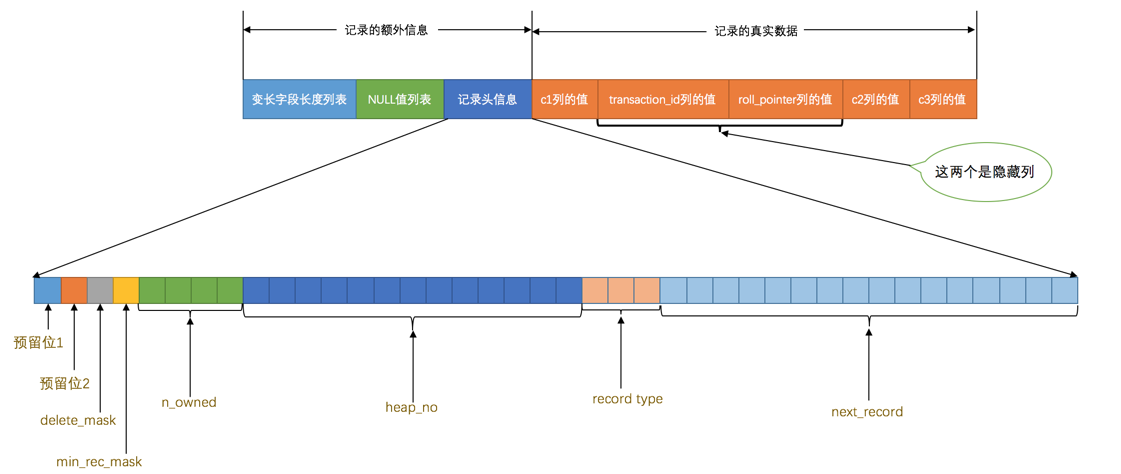
在 Compact 行格式中,把所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表,各变长字段数据占用的字节数按照列的顺序逆序存放。
MySQL 会为每条记录默认添加一些列:
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6 字节 | 行 ID,唯一标识一条记录 |
| transaction_id | 是 | 6 字节 | 事务 ID |
| roll_pointer | 是 | 7 字节 | 回滚指针 |
InnoDB 表对主键的生成策略:
- 优先使用用户自定义主键作为主键;
- 如果用户没有定义主键,则选取一个 Unique 键作为主键;
- 如果表中连 Unique 键都没有定义的话,则 InnoDB 会为表默认添加一个名为 row_id 的隐藏列作为主键。
Redundant 行记录格式

使用 Redundant 行格式的 CHAR(M) 类型的列是不会产生碎片的,CHAR(M) 占用的真实数据空间就是该字符集表示一个字符最多需要的字节数和 M 的乘积。在列的值允许为 NULL 的情况下,gbk 字符集表示一个字符最多需要2 个字节,那在该字符集下,M 的最大取值就是 32766(也就是:65532/2),也就是说最多能存储 32766 个字符;utf8 字符集表示一个字符最多需要 3 个字节,那在该字符集下,M 的最大取值就是 21844,就是说最多能存储 21844(也就是:65532/3)个字符。
Dynamic 和 Compressed 行记录格式
这两种行格式类似于 COMPACT 行格式,只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储字符串的前 768 个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。
另外,Compressed 行格式会采用压缩算法对页面进行压缩。
行溢出
一个页一般是 16KB,当记录中的数据太多,当前页放不下的时候,会把多余的数据存储到其他页中,这种现象称为 行溢出。
数据页结构
在页的 7 个组成部分中,我们自己存储的记录会按照我们指定的行格式存储到 User Records 部分。

表中记录的行格式示意图就是这样的:
不论我们怎么对页中的记录做增删改操作,InnoDB 始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。

小结:
InnoDB 存储引擎总是按照主键索引顺序进行存放。
InnoDB 为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做
数据页。一个数据页可以被大致划分为 7 个部分,分别是
File Header:表示页的一些通用信息,占固定的 38 字节。Page Header:表示数据页专有的一些信息,占固定的 56 个字节。Infimum + Supremum:两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的 26 个字节。User Records:真实存储我们插入的记录的部分,大小不固定。Free Space:页中尚未使用的部分,大小不确定。Page Directory:页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。File Trailer:用于检验页是否完整的部分,占用固定的 8 个字节。
每个记录的头信息中都有一个
next_record属性,从而使页中的所有记录串联成一个单链表。InnoDB会把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在Page Directory中,所以在一个页中根据主键查找记录是非常快的,分为两步:- 通过二分法确定该记录所在的槽。
- 通过记录的
next_record属性遍历该槽所在的组中的各个记录。
每个数据页的
File Header部分都有上一个和下一个页的编号,所以所有的数据页会组成一个双链表。为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的
LSN值,如果首部和尾部的校验和和LSN值校验不成功的话,就说明同步过程出现了问题。