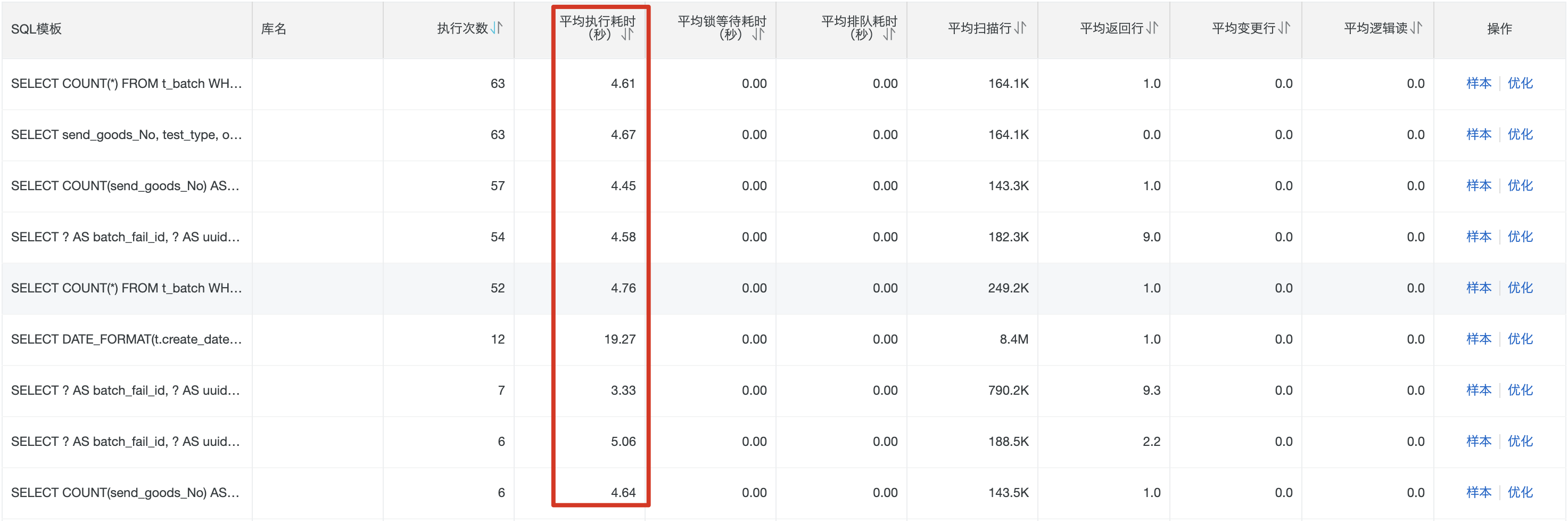
问题现象
原因分析
1 | mysql> select table_name,table_rows,CONCAT(TRUNCATE(SUM(data_length)/1024/1024,2),'MB') AS data_size, CONCAT(TRUNCATE(SUM(index_length)/1024/1024,2),'MB') AS index_size from information_schema.tables where TABLE_SCHEMA = 'mqm' and table_name='t_batch'; |
测试数据库
1 | 实例:10.138.22.192:3306/mqm |
1 | +----+-------------+---------+-------------+----------------------------------------------------------+---------------------------------------+---------+------+------+---------------------------------------------------------------------+ |
1 | explain select '' batch_fail_id,'' uuid_Fail,b.send_goods_No,b.test_type,b.order_no,b.row_no,b.bu,b.mtl_no,b.mtl_name,b.mtl_group,b.mtl_group_name,b.materiel_category_id,b.materiel_category_name,b.pattern_amount,b.plan_pattern_amount,b.goods_unit,b.plan_send_day,b.fact_send_Day,b.stock_Day,b.supply_code,b.supply_name,b.supply_check_level,b.sap_mark_id,b.sap_mark_name,b.syb_id,b.syb_name,b.check_style_id,b.check_style_name,b.check_type_id,b.check_type_name,b.QC_STATUS,b.QC_STATUS_INSTR_DATE,b.QC_NO,b.factory_code,b.goods_sort,b.price_unit,b.stock_price,b.LICHA,b.BSART,b.LGORT,b.plan_Date,b.TEST_CONCLUSION,b.IQC_manager_id,b.IQC_manager_name,b.iqc_leader_id,b.iqc_leader_name,b.test_complete_day,b.test_start_day,b.new_or_old,b.check_status_id,b.is_appeal,b.is_start_check,b.standard_type,b.check_reason,b.is_stop,b.check_time,b.instance_id,b.create_date createDate,b.delete_status |