简介
介绍:阿里云 RDS(Relational Database Service)是一种稳定可靠、可弹性伸缩的在线数据库服务。
功能:提供容灾、备份、恢复、监控、报警、高可用、迁移等全套解决方案,彻底解决数据库运维的烦恼。
数据库:支持 MySQL、SQL Server、PostgreSQL、 MariaDB 等引擎。
优势:便宜易用(按需变配,灵活计费)、高性能(最佳实践,CloudDBA)、灾备设计(自动备份,异地容灾)、高安全性(防 DDoS 攻击,链路加密,访问控制,安全审计)。
| 对比项 | 云数据库 RDS | 本地 IDC 自建 |
|---|---|---|
| 服务可用性 | 高可用架构 | 需自行搭建主备复制,保障高可用 |
| 数据可靠性 | 自动主备复制、数据备份、日志备份 | 需自行热备、冷备 |
| 系统安全性 | 防 DDoS 攻击,及时修复各种数据库安全漏洞 |
自行修复数据库安全漏洞 |
| 数据库备份 | 自动备份 | 自行实现,需要寻找备份存储以及定期演练 |
| 软硬件投入 | 无软硬件投入,按需付费 | 服务器成本相对较高 |
| 系统托管 | 无托管费用 | 服务器有托管费用 |
| 维护成本 | 无需专职运维 | 需要 DBA 专职运维 |
| 部署扩容 | 即时开通,弹性扩容 | 需要硬件采购、安装部署等工作,周期较长 |
| 资源利用率 | 按实际结算,100% 利用率 | 业务有高峰期和低峰期,资源利用率低 |
基本概念:
- 实例:一个独立占用物理内存的数据库服务进程,用户可以设置不同的内存大小、磁盘空间和数据库类型。
- 数据库:在一个实例下创建的逻辑单元,一个实例可以创建多个数据库,数据库在实例内的命名唯一。
- 地域:是指物理的数据中心。
- 可用区:是指在同一地域内,电力和网络互相独立的物理区域。
- 连接数:实例当前总连接数,包括活跃连接数和总连接数。
- IOPS:实例的每秒
I/O请求次数,单位:次/秒,衡量随机访问的性能。
流程
选型(owner:架构师)-> 申请(owner:项目经理)-> 交付(owner:云管理)-> 运维(owner:DBA)
选型
产品系列
| 系列 | 说明 | 适用场景 |
|---|---|---|
| 基础版 | 单节点实例,可实现超高的性价比,请参见基础版 | 个人学习 / 开发测试 |
| 高可用版 | 一主一备高可用架构,适合 80% 以上用户场景 |
大中型企业生产数据库 |
| 三节点企业版 | 一主两备三节点架构,提供金融级可靠性,请参见三节点企业版 | 大型企业核心数据库 |
功能对比
| 功能 | 基础版 | 高可用版(推荐) | 三节点企业版(原金融版) |
|---|---|---|---|
| MySQL 5.7 / 8.0 | MySQL 5.5 / 5.6 / 5.7 / 8.0 | MySQL 5.6 / 5.7 | |
| 监控与报警 | 支持 | 支持 | 支持 |
| IP白名单 | 支持 | 支持 | 支持 |
| 备份与恢复 | 支持 | 支持 | 支持 |
| 参数设置 | 支持 | 支持 | 支持 |
| 日志管理 | 不支持 | 支持 | 支持 |
| 主备库切换 | 不支持 | 支持 | 支持 |
| SSL | 不支持 | 支持 | 支持 |
| 透明数据加密 | 不支持 | 支持 | 支持 |
| 性能优化 | 不支持 | 支持 | 支持 |
| 迁移可用区 | 不支持 | 支持 | 支持 |
| 读写分离 | 不支持 | 支持 | 支持 |
| 只读实例 | 不支持 | 支持(另计费) | 支持(另计费) |
| SQL洞察 | 不支持 | 支持(另计费) | 支持(免费使用) |
存储类型
| 存储类型 | 说明 | 支持系列 |
|---|---|---|
本地 SSD 盘 |
与数据库引擎位于同一节点,I/O 延时低 |
高可用版 / 三节点企业版 |
SSD 云盘 |
基于分布式存储架构的弹性块存储设备,实现计算与存储分离 | 基础版 |
ESSD 云盘 |
增强型 SSD 云盘,是阿里云全新推出的超高性能云盘产品 |
高可用版 / 三节点企业版 |
特性对比
| 对比项 | 本地 SSD 盘(推荐) | SSD 云盘 | ESSD 云盘 |
|---|---|---|---|
| I/O 性能 | ★★★★★ | ★★★★ | ★★★★★ |
| 功能完备度 | ★★★★★ | ★★★ | ★★★ |
| 规格配置灵活性 | ★★★ | ★★★★★ | ★★★★★ |
| 弹性扩展能力 | ★★★ | ★★★★★ | ★★★★★ |
功能对比
| 对比项 | 本地 SSD 盘 | SSD 云盘 / ESSD 云盘 |
|---|---|---|
| 最大存储容量 | 6 TB | 6 TB |
| 网络类型 | 经典网络和 VPC |
经典网络和 VPC |
| 弹性升降级 | 支持,时间为小时级别,取决于数据量大小 | 支持,一般只需要 10 分钟 |
| 迁移可用区 | 支持 | 开发中 |
| 只读实例 | 支持 | 部分引擎支持 |
| 读写分离 | 支持 | 部分引擎支持 |
| SQL审计 | 支持 | 开发中 |
| CloudDBA | 支持 | 部分引擎支持 |
| SSL加密 和 TDE | 支持 | 部分引擎支持 |
| 备份方式 | 物理 & 逻辑备份 | 快照备份 |
| 按备份集恢复 | 支持 | 支持 |
| 按时间点恢复 | 支持 | 支持 |
实例规格
通用型 vs 独享型

| 规格族 | 规格代码 | CPU / 内存 | 存储空间 | 最大连接数 | IOPS | 包月价 |
|---|---|---|---|---|---|---|
| 通用型 | rds.mysql.c1.xlarge | 8 核 32GB | 500GB | 8000 | 12000 | ¥1480.00 |
| 独享型(推荐) | mysql.x4.xlarge.2 | 8 核 32GB | 500GB | 5000 | 9000 | ¥1800.00 |
| 规格代码 | CPU核数 | 内存(GB) | 连接数 | IOPS | TPS | QPS |
|---|---|---|---|---|---|---|
| mysql.x8.medium.2 | 2 | 16 | 2500 | 4500 | 391 | 7054 |
| mysql.x8.large.2 | 4 | 32 | 5000 | 9000 | 794 | 14297 |
| mysql.x8.xlarge.2 | 8 | 64 | 10000 | 18000 | 1541 | 27751 |
| mysql.x8.2xlarge.2 | 16 | 128 | 20000 | 36000 | 2672 | 48102 |
| rds.mysql.st.d13 | 30 | 220 | 64000 | 20000 | 3693 | 65508 |
网络类型
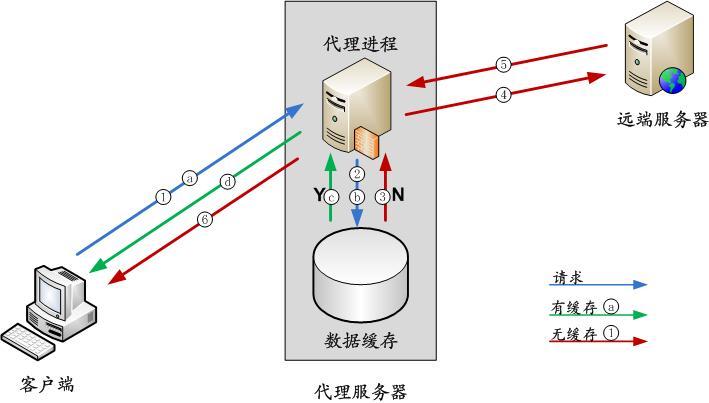
- 经典网络:实例之间不通过网络进行隔离,只能依靠实例自身的白名单策略来阻挡非法访问。
- 专有网络:
VPC是一种隔离的网络环境,安全性和性能均高于传统的经典网络,推荐使用专有网络。
最佳实践
| 选项 | 配置 |
|---|---|
| 地域 | 华北 1(青岛) |
| 数据库版本 | MySQL 5.7 |
| 系列 | 高可用版 |
| 存储类型 | 本地 SSD 盘 |
| 可用区 | 可用区 C / 可用区 B |
| 网络类型 | 专有网络 |
| 规格 | 8 核 32G(独享套餐) |
| 存储空间 | 500GB |
运维
开通服务
登录:入口
RAM账号:raohui@1596633715004367.onaliyun.com
快速使用
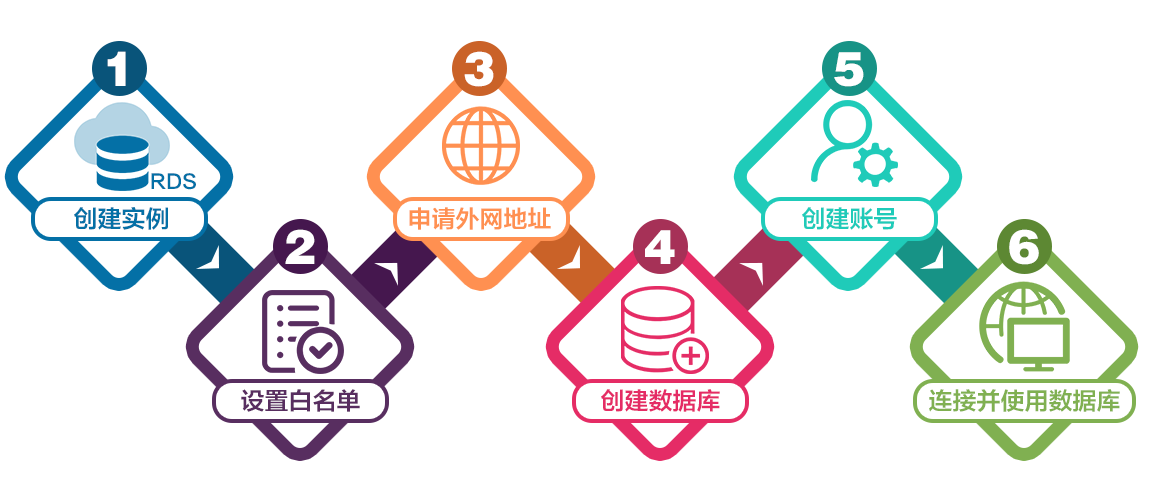
创建实例:云管理团队提供
设置白名单:将通用白名单模式切换为高安全白名单模式,拥有更高的安全性
| 网络类型 | 白名单 |
|---|---|
| 专有网络 | 10.138.0.0/16,10.153.0.0/16,10.163.0.0/16,10.133.0.0/16,10.190.0.0/16 |
创建数据库:推荐库名与应用名称尽量一致,由小写字母、数字、下划线或中划线组成,默认字符集 utf8
创建账号
| 账号类型 | 说明 | 权限 |
|---|---|---|
| 高权限账号 | 拥有实例下所有数据库的所有权限,一个实例中只能创建一个 | 列表 |
| 普通账号 | 四种类型权限:只读 / 读写 / 仅DDL / 仅DML | 列表 |
密码:由大写字母、小写字母、数字、特殊字符中的任意三种组成,特殊字符为 !@#$%^&*()_+-=
监控告警
监控
| 实例类型 | 5秒/次 | 60秒/次 | 300秒/次 |
|---|---|---|---|
| 基础版 | 不支持 | 免费支持 | 默认配置 |
| 高可用版、三节点企业版:内存 < 8G | 不支持 | 免费支持 | 默认配置 |
| 高可用版、三节点企业版:内存 >= 8G | 付费支持 | 默认配置 | 免费支持 |
备份恢复
| 备份方式 | 默认 | 存储 | 恢复 | 计费 |
|---|---|---|---|---|
| 默认备份 | 开启 | 实例所在地域 | 当前地域的新实例或原实例 | 免费额度 = 50% * 存储空间 |
| 跨地域备份 | 关闭 | 另一个地域 | 源地域或目的地域的新实例 | 存储 0.001元/GB/小时 + 流量费 |
默认备份

异地容灾
场景:对于数据可靠性有强需求的业务场景或是有监管需求的金融业务场景。
- 灾备实例:通过数据传输服务(
DTS)实现主实例和异地灾备实例之间的实时同步,灾备实例与主实例配置完全相同,当主实例所在区域发生突发性自然灾害等状况,主节点(Master)和备节点(Slave)均无法连接时,可将异地灾备实例切换为主实例,在应用端修改数据库链接地址后,即可快速恢复应用的业务访问,计费:灾备实例 + DTS。 - 跨地域备份:自动将本地备份文件复制到另一个地域的
OSS上,文件可保留7~1825天,即最多保留5年,计费:存储(0.001元/GB/小时) + 流量费。
高可用
购买时建议选择高可用版,或更高的三节点企业版,高可用版实例有一个备实例,三节点企业版实例有两个备实例,主备实例的数据会实时同步,业务只能访问主实例,备实例仅作为备份形式存在,不提供业务访问。
- 自动切换:实例默认为自动切换,当主实例出现故障无法访问时,会实现秒级自动切换到备实例。
- 手动切换:即使自动切换是开启状态,也可以手动进行主备切换。
单可用区

多可用区
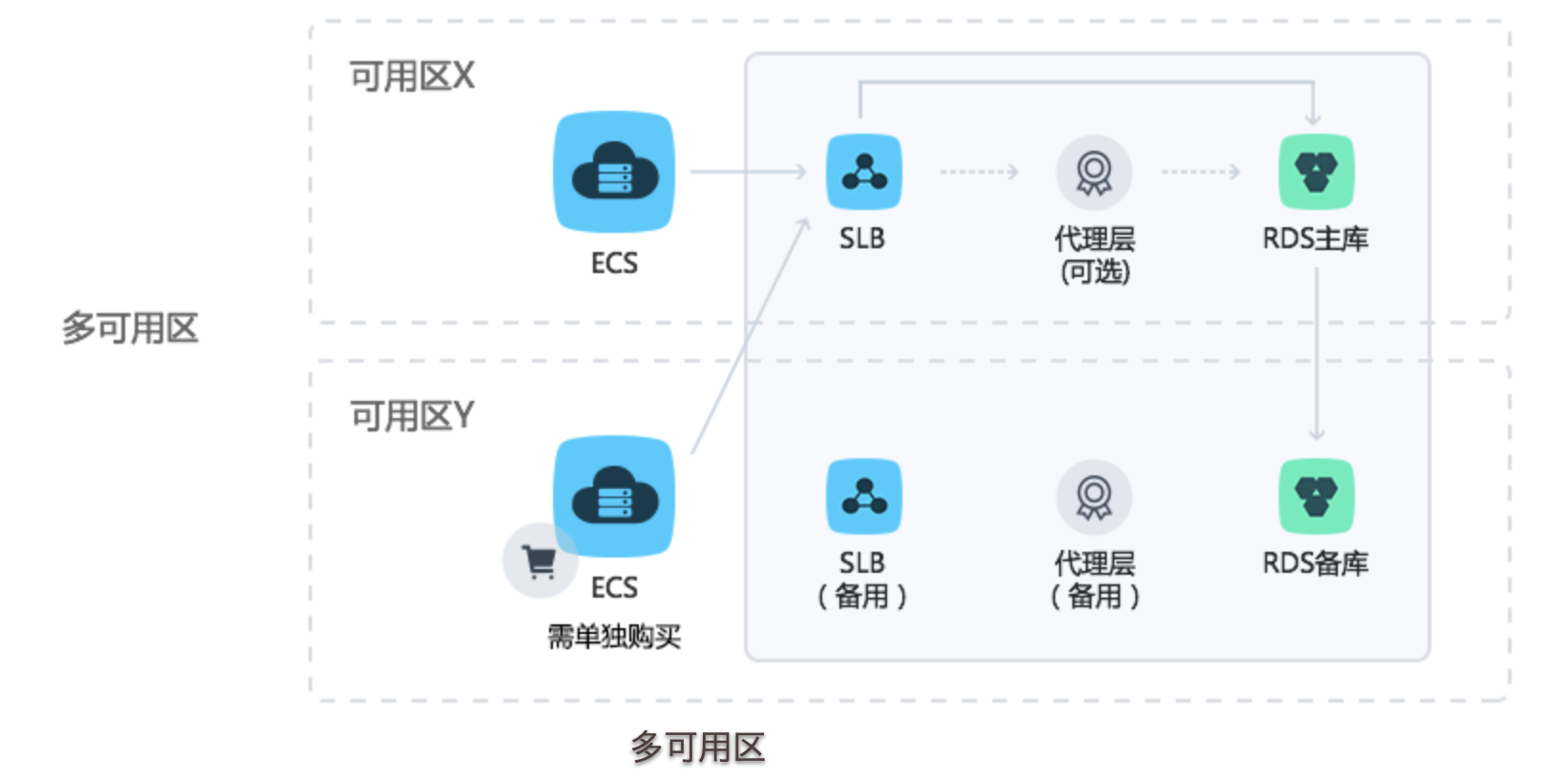
读写分离
场景:在对数据库有少量写请求,但有大量读请求的应用场景下,单个实例可能无法承受读取压力,甚至对业务产生影响,为了分担数据库压力,创建只读实例,满足大量的数据库读取需求,增加应用的吞吐量。
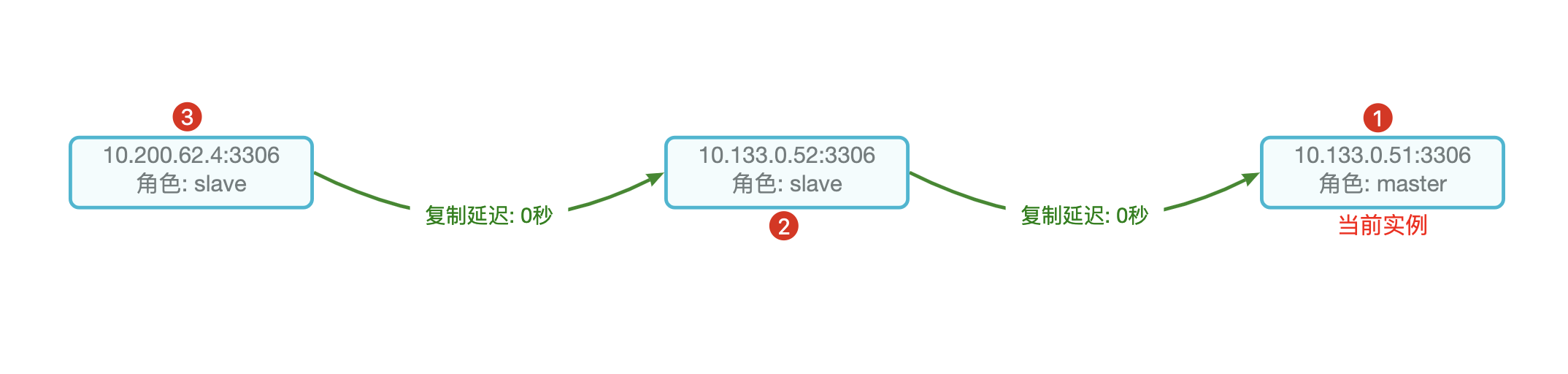
原理:创建只读实例时会从备实例复制数据,数据与主实例一致,主实例的数据更新也会在主实例完成操作后立即自动同步到所有只读实例,也可以在只读实例上设置只读实例延时复制。
只读实例 vs 主备实例 vs 灾备实例

数据安全
提供了多样化的安全加固功能来保障用户数据的安全,其中包括但不限于:
① 网络:IP 白名单、VPC 网络、SSL(安全套接层协议)
② 存储:TDE(透明数据加密)、自动备份
③ 容灾:同城容灾(多可用区实例)、异地容灾(两地多中心)
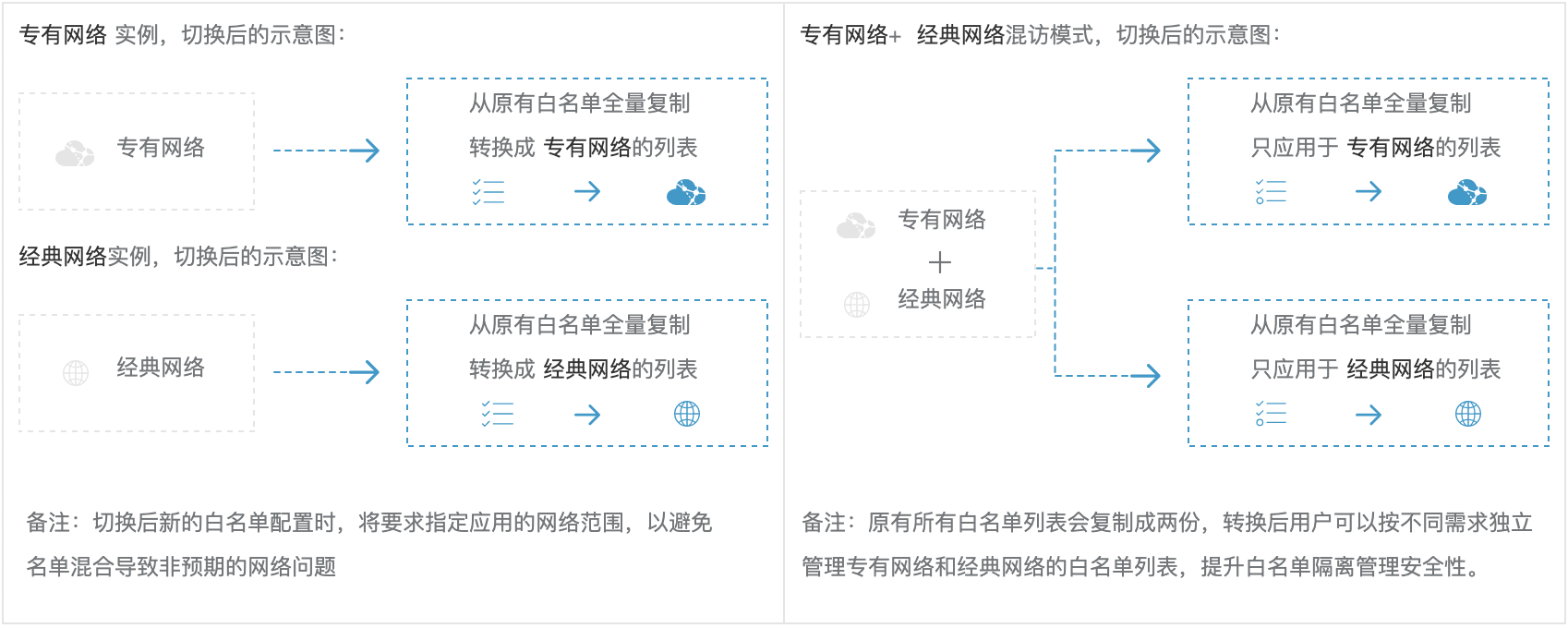
白名单:可以让实例得到高级别的访问安全保护,建议定期维护。
- 默认的
IP白名单只包含默认地址127.0.0.1,表示任何设备均无法访问该RDS实例 0.0.0.0/0表示允许任何设备访问RDS实例,请谨慎使用- 高安全白名单模式下,经典网络白名单分组适用于公网访问,如果有公网设备要访问
RDS实例,请将公网设备IP地址添加到经典网络白名单分组
SSL加密:SSL 在传输层对网络连接进行加密,能提升通信链路数据的安全性和完整性,但会同时增加网络连接响应时间,开通 SSL 加密后,应用或者客户端连接 RDS 时需要配置 SSL CA 证书。
透明数据加密 TDE:TDE(Transparent Data Encryption)可对数据文件执行实时 I/O 加密和解密,数据在写入磁盘之前进行加密,从磁盘读入内存时进行解密。TDE 不会增加数据文件的大小,开发人员无需更改任何应用程序,即可使用 TDE 功能。
云盘加密:阿里云免费提供云盘加密功能,基于块存储对整个数据盘进行加密,即使数据备份泄露也无法解密,最大限度保护数据安全,而且加密不会影响业务,应用程序也无需修改。
诊断优化
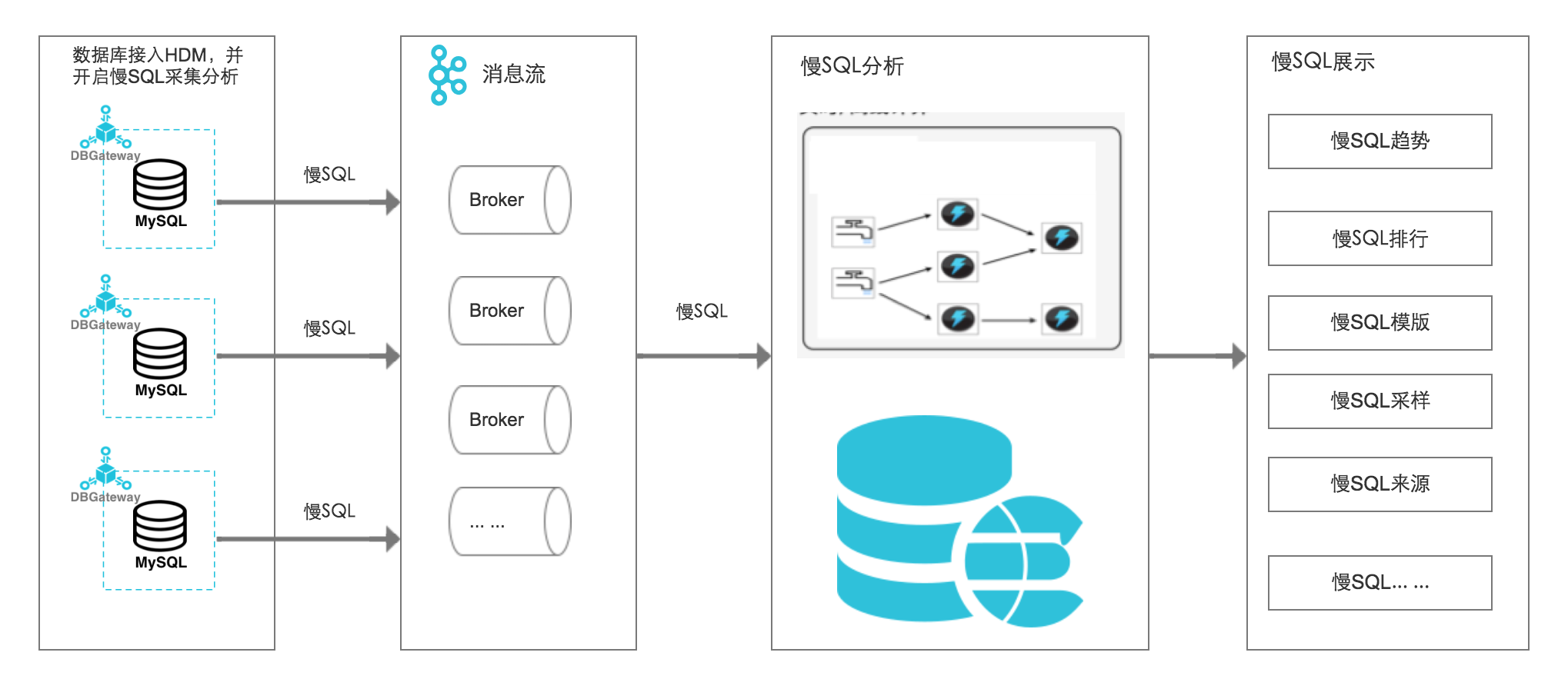
日志管理:错误日志、慢日志、主备切换日志,帮助故障定位分析
错误日志:记录
1个月内数据库运行出错的日志。慢日志:对
1个月内数据库中执行时间超过1秒(可以在参数设置 中修改long_query_time来设置)的SQL语句进行统计汇总,控制台每分钟更新一次,实时的慢日志明细可以查看mysql.slow_log表。主备切换日志:该功能适用于高可用版、三节点企业版。