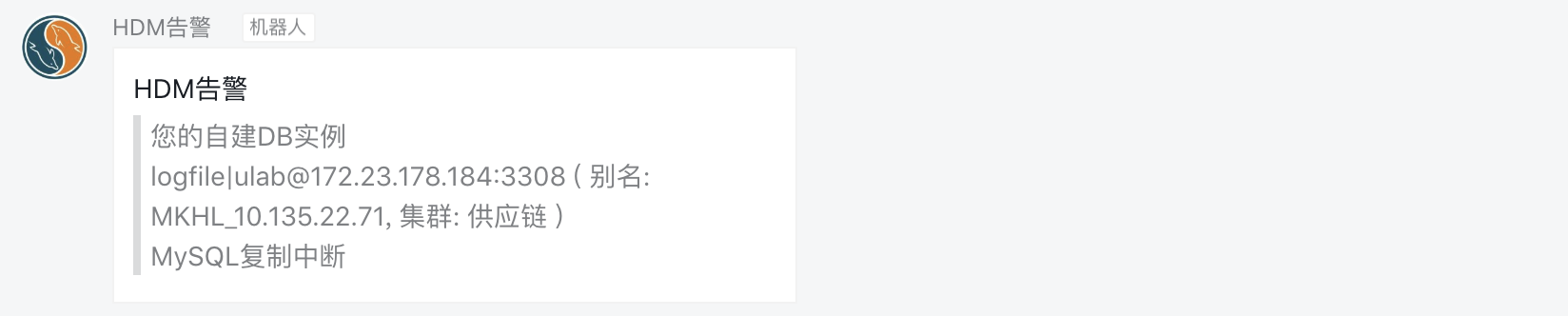
Slave_IO_Running: No
找不到初始日志
- 报错信息
1 | Slave_IO_Running: No |
- 原因分析
该错误发生在从库 io 进程从主库拉取日志时,发现主库的 mysql_bin.index 文件中第一个文件不存在,出现此类报错可能有两个原因:
1)Slave 由于某种原因停了好长一段是时间,当你重启 Slave 复制的时候,在主库上找不到相应的 binlog 。
2)由于某些设置主库上的 binlog 被删除了,导致从库获取不到对应的 binlog。
1 | [root@hop02 mzjh]# ll | grep mysql-bin |
- 解决方法
为了避免数据丢失,需要重新搭建 Slave
磁盘空间不足,日志被截断
- 报错信息
1 | Slave_IO_Running: No |
- 原因分析
该错误和主库的空间和 sync_binlog 配置有关,当主库 sync_binlog = N 不等于 1 且磁盘空间满时,MySQL 每写 N 次 binlog,系统才会同步到磁盘,但是由于存储日志的磁盘空间满而导致 MySQL 没有将日志完全写入磁盘,binlog event 被截断,从库读取该 binlog 时就会报错 binlog truncated in the middle of event。
- 解决方法
在从库重新指向到主库下一个可用的 binlog 并且从初始化的位置开始:
1 | stop slave; |
Slave_SQL_Running: No
1026:HA_ERR_RBR_LOGGING_FAILED
- 报错信息
1 | Slave_IO_Running: Yes |
原因分析
Master和Slave数据不一致导致Slave服务器重启,事务回滚造成
解决方法
- 手动跳过
1
2
3stop slave ;
set global sql_slave_skip_counter=1;
start slave ;
1205:HA_ERR_LOCK_WAIT_TIMEOUT
报错信息:
1 | Last_Error: Could not execute Update_rows event on table haier.haier_weixin_user; Lock wait timeout exceeded; try restarting transaction, Error_code: 1205; handler error HA_ERR_LOCK_WAIT_TIMEOUT; the event's master log mysql-bin.000001, end_log_pos 629671840 |
1032:HA_ERR_END_OF_FILE
- 报错信息
1 | Slave_IO_Running: Yes |
- 原因分析
1 | 191208 23:06:33 [ERROR] Slave SQL: Could not execute Update_rows event on table haier.haier_yonghuzhongxin_shebei; Can't find record in 'haier_yonghuzhongxin_shebei', Error_code: 1032; handler error HA_ERR_END_OF_FILE; the event's master log mysql-bin.000030, end_log_pos 130643848, Error_code: 1032 |
- 解决方法
1 | stop slave; |
1032:HA_ERR_KEY_NOT_FOUND
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Delete_rows event on table hce.dim_r_cei_general; Can’t find record in ‘dim_r_cei_general’, Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event’s master log mysql-bin.000273, end_log_pos 139807561