安装
1、Github 下载 JSONView-for-Chrome,并解压缩到相应目录。
2、打开 Chrome 扩展程序,点击 “加载正在开发的扩展程序…” -> 选择插件目录(…\JSONView-for-Chrome-master\WebContent)。
3、安装完成,重新加载。
1、Github 下载 JSONView-for-Chrome,并解压缩到相应目录。
2、打开 Chrome 扩展程序,点击 “加载正在开发的扩展程序…” -> 选择插件目录(…\JSONView-for-Chrome-master\WebContent)。
3、安装完成,重新加载。
vue-devtools 是一款基于浏览器的插件,用于调试 vue 应用,这可以极大地提高我们的调试效率。
1 | git clone https://github.com/vuejs/vue-devtools.git |
如果编译失败,可直接将已编译好的 .crx 文件,拖入 Chrome 拓展程序 页面。
1 | 链接: https://pan.baidu.com/s/139hspAnspD7bJbo81xigmg |


基础:前端入门基础
进阶:框架:Vue,技术全家桶
bilibili | 极客时间 | 掘金 | Github | 码云
脚手架搭建
1 | npm -V |
目录结构
1 | . |
组件化思想
几乎任意类型的应用界面都可以抽象为一个组件树:

单:支撑全量 MySQL、云数据库、Redis 在内的智能运维能力,为应用提供可视功能和增值服务。
横向:
纵向:
| 领域 | 接口人 |
|---|---|
| 市场 ToB | – |
| 用户运营 | 潘广通 |
| 市场中台 | 聂明明 |
| 研发 | 赵俊 |
| 制造 | 徐金良 |
| 供应链 | 潘广通 |
| 海外 | 饶辉 |
| 售后 | 王建坤 |
PSI 技术黑板报
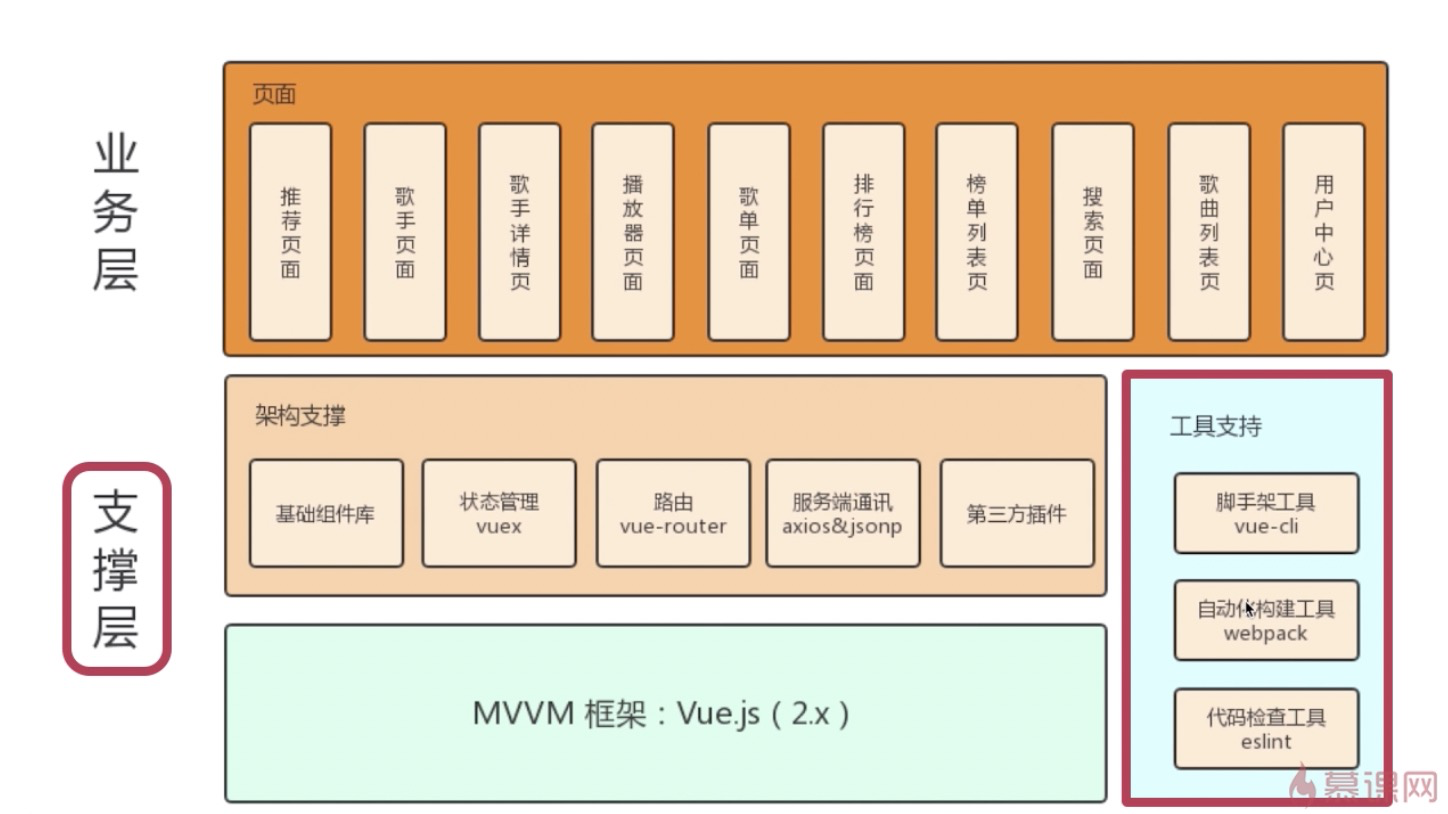
方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用
keepalived(只是一种工具)会自动切换到备库,这个过程对业务层是透明的,无需修改代码或配置。方案二:双主架构,两个主库同时提供服务,负载均衡

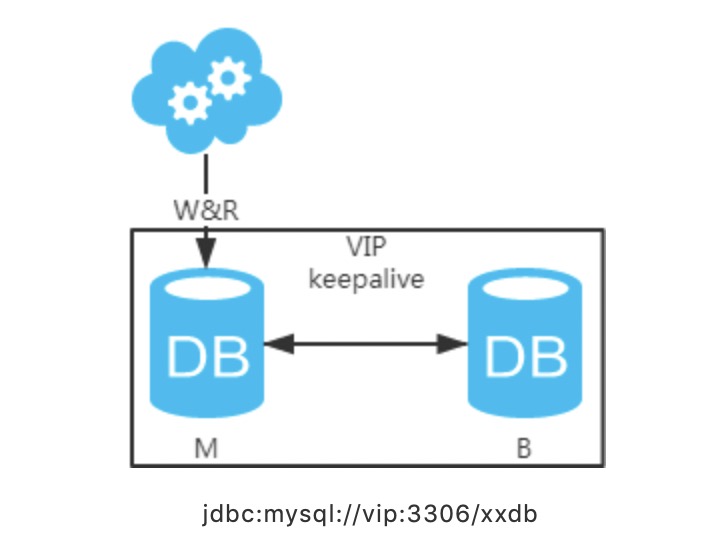
方案三:主从架构,一主多从,读写分离
方案四:双主 + 主从架构,看似完美的方案

第一类:主库和从库一致性解决方案

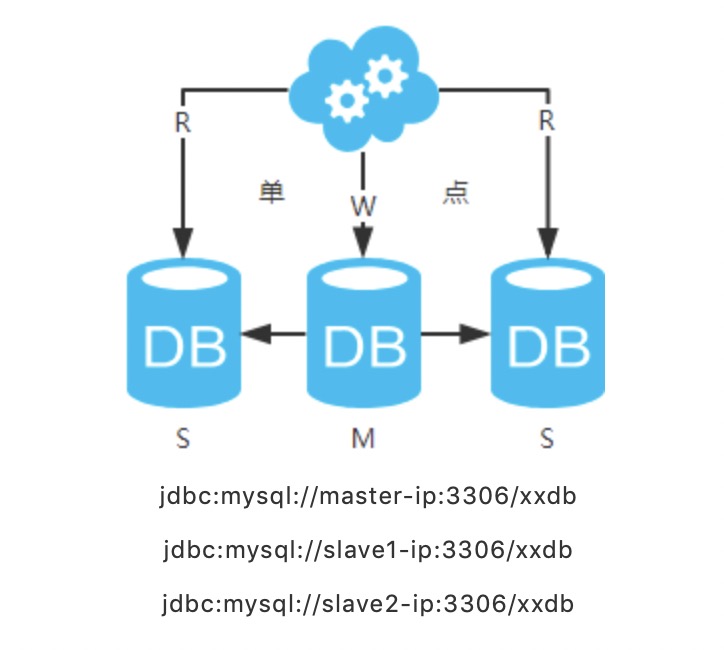
注:图中圈出的是数据同步的地方,数据同步(从库从主库拉取 binlog 日志,再执行一遍)是需要时间的,这个同步时间内主库和从库的数据会存在不一致的情况。如果同步过程中有读请求,那么读到的就是从库中的老数据。如下图。

既然知道了数据不一致性产生的原因,有下面几个解决方案供参考:
1、直接忽略,如果业务允许延时存在,那么就不去管它。
2、强制读主,采用主备架构方案,读写都走主库。用缓存来扩展数据库读性能 。有一点需要知道:如果缓存挂了,可能会产生雪崩现象,不过一般分布式缓存都是高可用的。

3、选择读主,写操作时根据库 + 表 + 业务特征生成一个 key 放到 Cache 里并设置超时时间(大于等于主从数据同步时间)。读请求时,同样的方式生成 key 先去查 Cache,再判断是否命中。若命中,则读主库,否则读从库。代价是多了一次缓存读写,基本可以忽略。
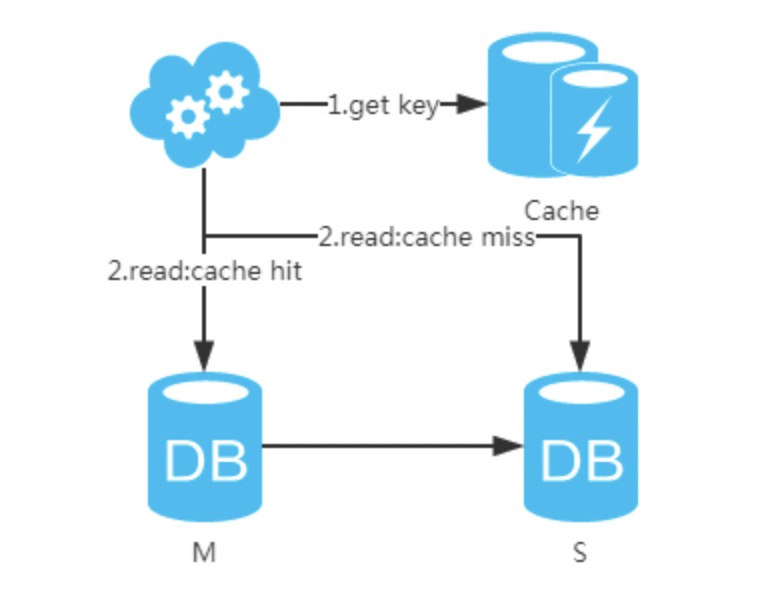
4、半同步复制,等主从同步完成,写请求才返回。就是大家常说的“半同步复制” semi-sync。这可以利用数据库原生功能,实现比较简单。代价是写请求时延增长,吞吐量降低。
5、数据库中间件,引入开源( mycat 等)或自研的数据库中间层。个人理解,思路同选择读主。数据库中间件的成本比较高,并且还多引入了一层。

第二类:DB 和缓存一致性解决方案

先来看一下常用的缓存使用方式:
第一步:淘汰缓存;
第二步:写入数据库;
第三步:读取缓存?返回:读取数据库;
第四步:读取数据库后写入缓存。
注:如果按照这种方式:图一、不会产生 DB 和缓存不一致问题;图二、会产生 DB 和缓存不一致问题,即 4.read 先于 3.sync 执行。如果不做处理,缓存里的数据可能一直是脏数据。解决方式如下:
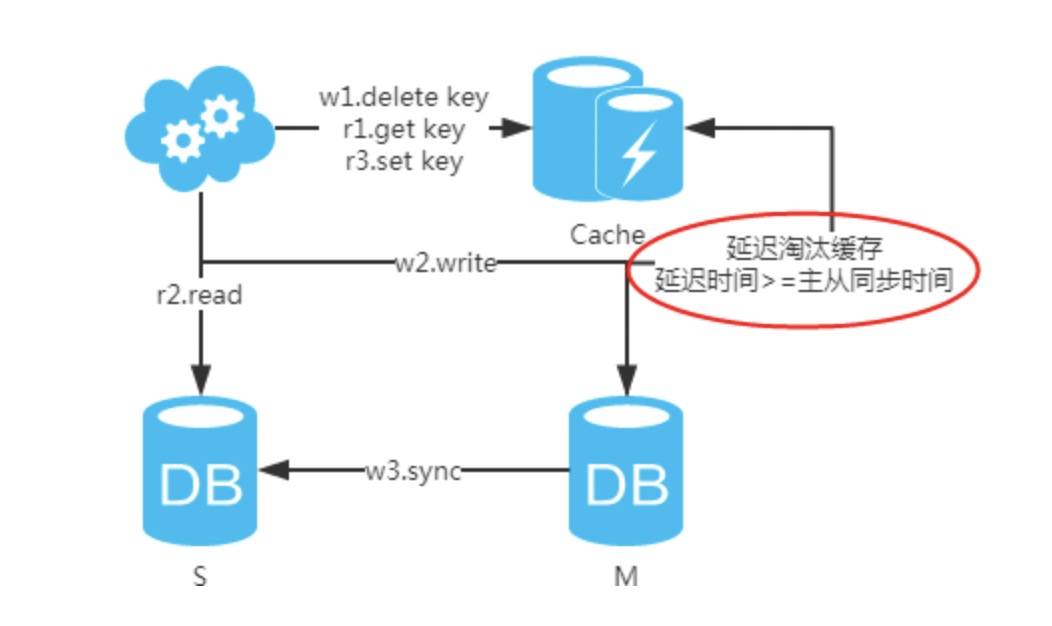
注:设置缓存时,一定要加上失效时间,以防延时淘汰缓存失败的情况!
mall 项目是一套电商系统,包括前台商城系统及后台管理系统,基于 SpringBoot + MyBatis 实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
后端
| 技术 | 说明 |
|---|---|
| Spring Boot | 容器 + MVC 框架 |
| Spring Security | 认证和授权框架 |
| MyBatis | ORM 框架 |
| MyBatis Generator | 数据层代码生成 |
| PageHelper | MyBatis 物理分页插件 |
| Swagger UI | 文档生产工具 |
| Elasticsearch | 搜索引擎 |
| RabbitMQ | 消息队列 |
| Redis | 分布式缓存 |
| MongoDB | NoSQL 数据库 |
| Docker | 应用容器引擎 |
| Druid | 数据库连接池 |
| OSS | 对象存储 |
| JWT | JWT 登录支持 |
| Lombok | 简化对象封装工具 |
| Hibernator-Validator | 验证框架 |
| LogStash | 日志收集工具 |
| Kibana | 为 Elasticsearch 设计的开源分析和可视化平台 |
前端
| 技术 | 说明 |
|---|---|
| Vue | 前端框架 |
| Vue-router | 路由框架 |
| Vuex | 全局状态管理框架 |
| Element | 前端 UI 框架 |
| Axios | 前端 HTTP 框架 |
| v-charts | 基于 Echarts 的图表框架 |
| Js-cookie | cookie 管理工具 |
| nprogress | 进度条控件 |
| vue-element-admin | 项目脚手架参考 |
| 工具 | 说明 |
|---|---|
| IDEA | 开发 IDE |
| Redis Desktop | Redis 客户端连接工具 |
| Robomongo | MongoDB 客户端连接工具 |
| XShell | Linux 远程连接工具 |
| Navicat | 数据库连接工具 |
| Power Designer | 数据库设计工具 |
| Axure | 原型设计工具 |
| XMind | 思维导图设计工具 |
| ScreenToGif | gif 录制工具 |
| ProcessOn | 流程图绘制工具 |
| PicPick | 图片处理工具 |
| Snipaste | 屏幕截图工具 |
系统微服务架构图


1 | mall |
| 技术 | 说明 | 官网 |
|---|---|---|
| Vue | 前端框架 | https://vuejs.org/ |
| Vue-router | 路由框架 | https://router.vuejs.org/ |
| Vuex | 全局状态管理框架 | https://vuex.vuejs.org/ |
| Element | 前端 UI 框架 | https://element.eleme.io/ |
| Axios | 前端 HTTP 框架 | https://github.com/axios/axios |
| v-charts | 基于 Echarts 的图表框架 | https://v-charts.js.org/ |
| Js-cookie | cookie 管理工具 | https://github.com/js-cookie/js-cookie |
| nprogress | 进度条控件 | https://github.com/rstacruz/nprogress |
| vue-element-admin | 项目脚手架参考 | https://github.com/PanJiaChen/vue-element-admin |
1 | src -- 源码目录 |
前端项目部署:
1、下载前端代码 mall-admin-web
2、VS Code 打开代码
3、打开控制台,通过 npm install 命令安装相关依赖
4、修改 dev.env.js 文件中 BASE_API,使用线上 API 进行访问,线上地址为:http://120.27.63.9:8080
1 |
|
5、通过 npm run dev 命令,启动 mall-admin-web
6、访问地址 http://localhost:8090 查看效果
后端项目部署
1 | # 构建镜像 |
1 | # 删除镜像 |
常用命令
1 | docker search java:在 Docker Hub(或阿里镜像)仓库中搜索关键字(如java)的镜像 |
Dockerfile
1 | FROM java:8 |
对于众多企业来说,云的优势越来越明显,出于想使用成熟技术、减少运维成本、提升系统性能等方面的考虑,纷纷向“云”看齐。不过,在涉及到本地或云端的具体实施过程时,一个较为重要的问题就是数据的迁移。如何使用云服务商提供的迁移工具可以实现在自建应用不停服较长时间的情况下,平滑地完成自建数据库的迁移上云是一个首先需要解决的问题。
以阿里云为例:主要使用 DTS 服务,实现本地 IDC 与阿里云 RDS 的数据迁移。
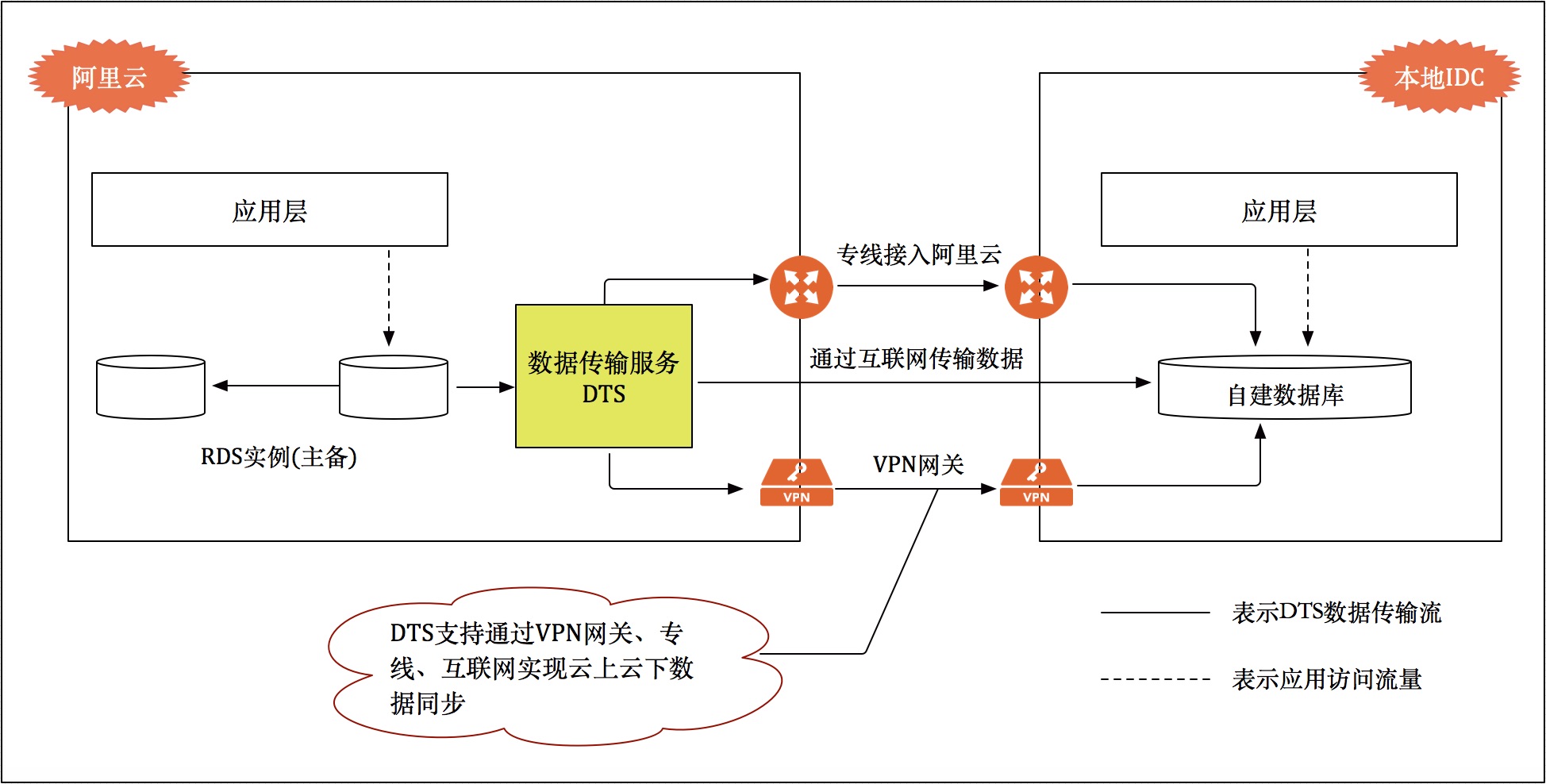
不通的迁移方案应对不同的场景:
| 场景 | 迁移方案 |
|---|---|
| 本地 IDC 与阿里云机房,有专线 | 通过专线迁移 |
| 本地 IDC 与阿里云,无专线,但数据库可开通公网 IP | 通过公网 IP 迁移 |
| 本地 IDC 与阿里云,无专线,且数据库不可开通公网 IP | 通过 ECS 自建数据库与本地自建数据库搭成主从,再通过阿里云内网迁移 |
| 本地 IDC 与阿里云机房,有专线,但不是同一个主账号 | 通过 RDS 中转迁移,参考 使用DTS跨阿里云账号迁移RDS数据 |
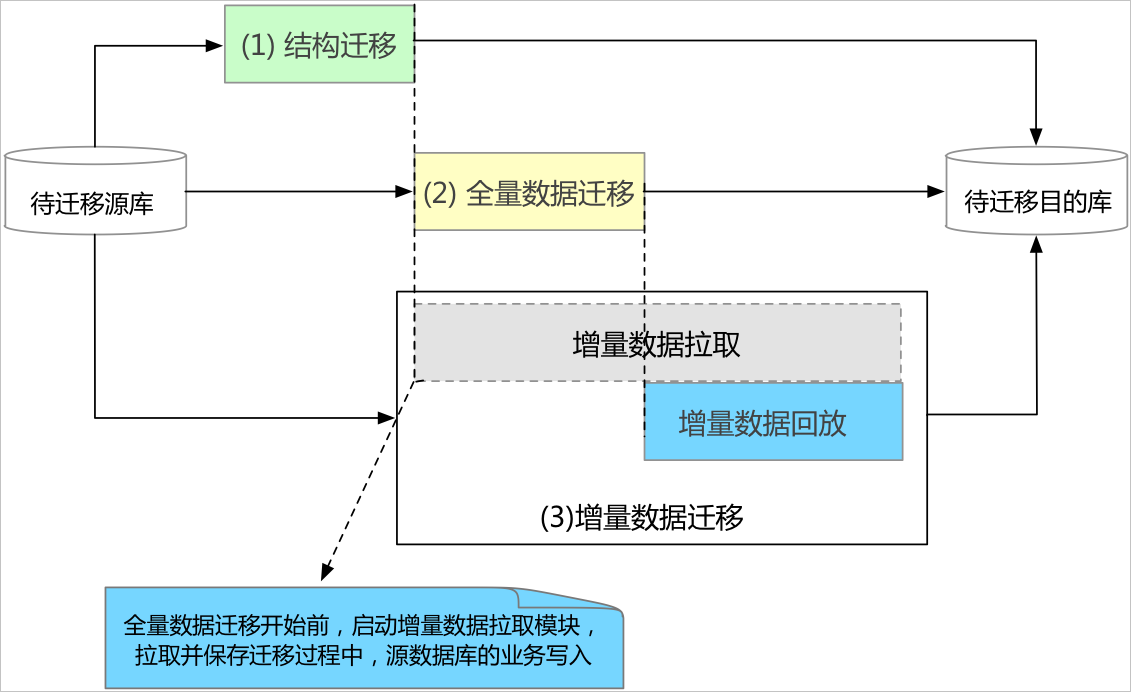
准备事项:
注意事项:
基本信息:
| 源库信息 | 目标库信息 | |
|---|---|---|
| 数据库版本 | MariaDB 10.1.19 | MySQL 5.7 |
| 机房区域 | 北京亦庄 | 华为2(北京) |
| 数据量 | 170 GB | ~ |
| 要求 | 1. 分钟级停服;2. 失败可回退。 | ~ |
| 迁移方案 | 公网 IP + 结构 + 全量 + 增量 | ~ |
操作步骤:
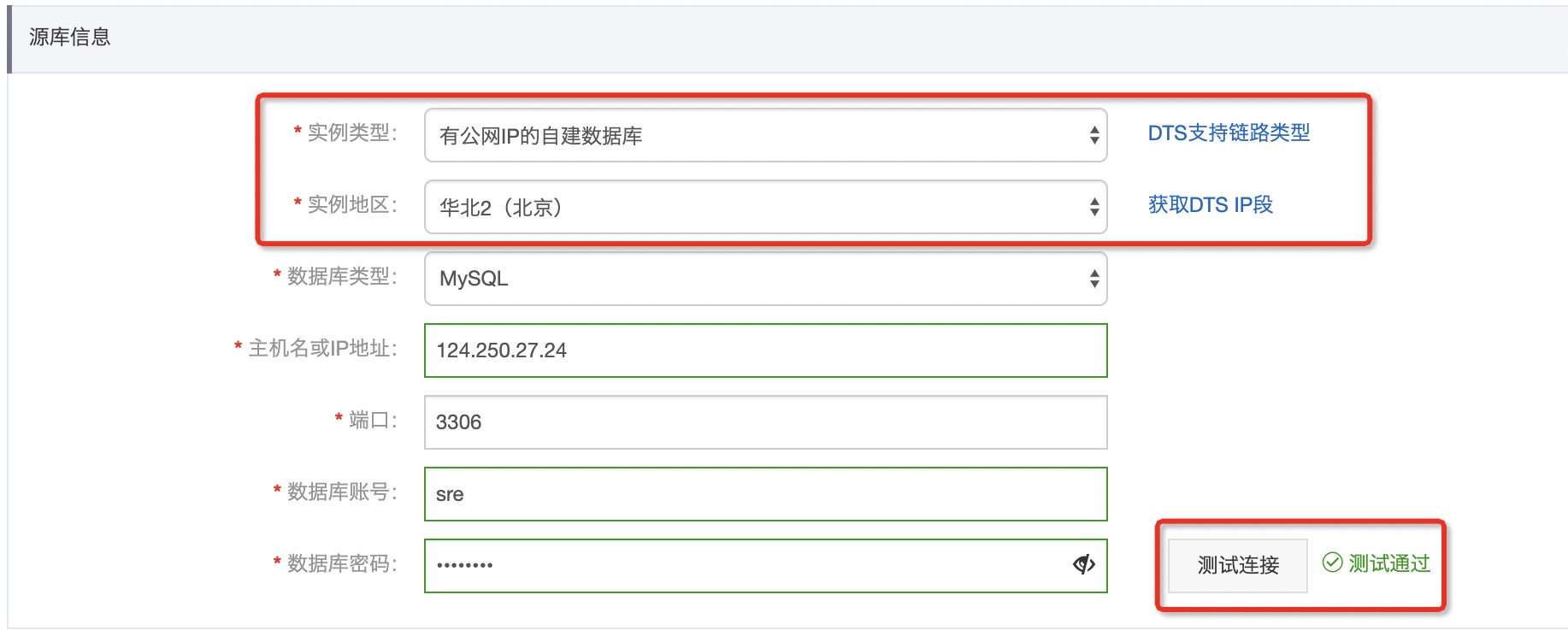
1、进入 DTS 控制台,创建迁移任务

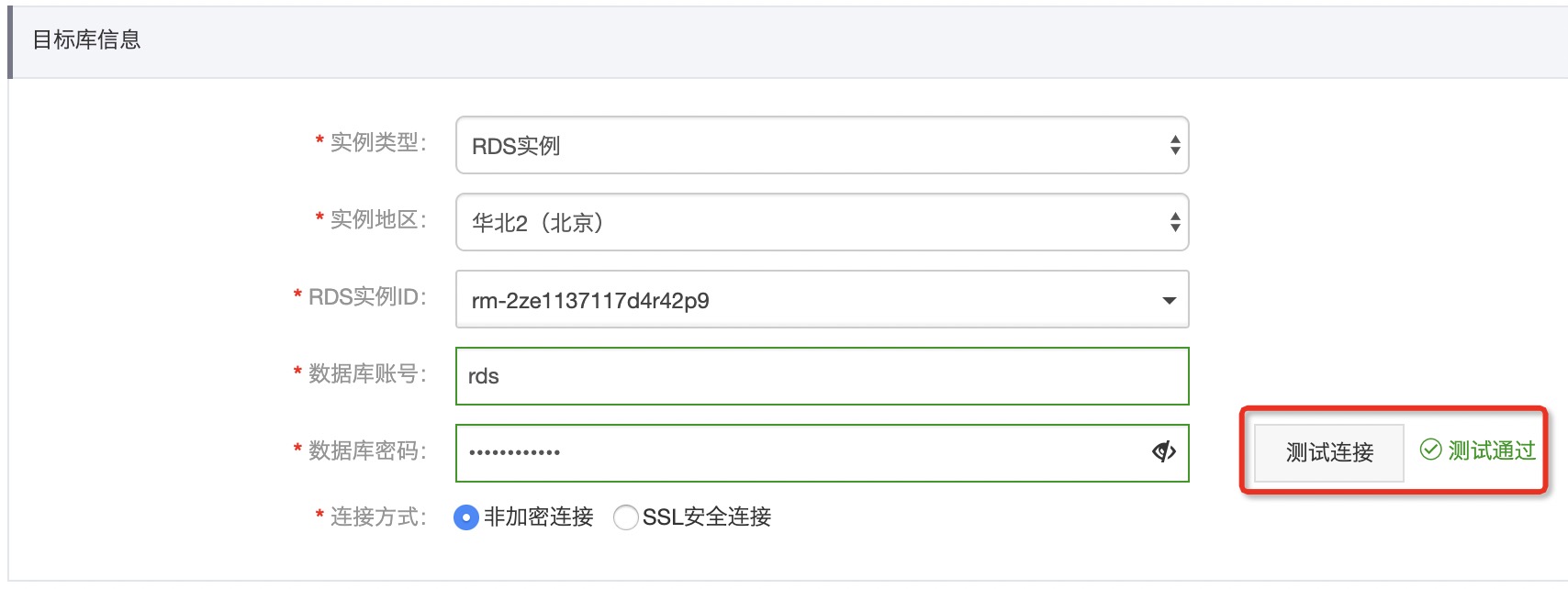
2、配置源库和目标库,并连接测试通过
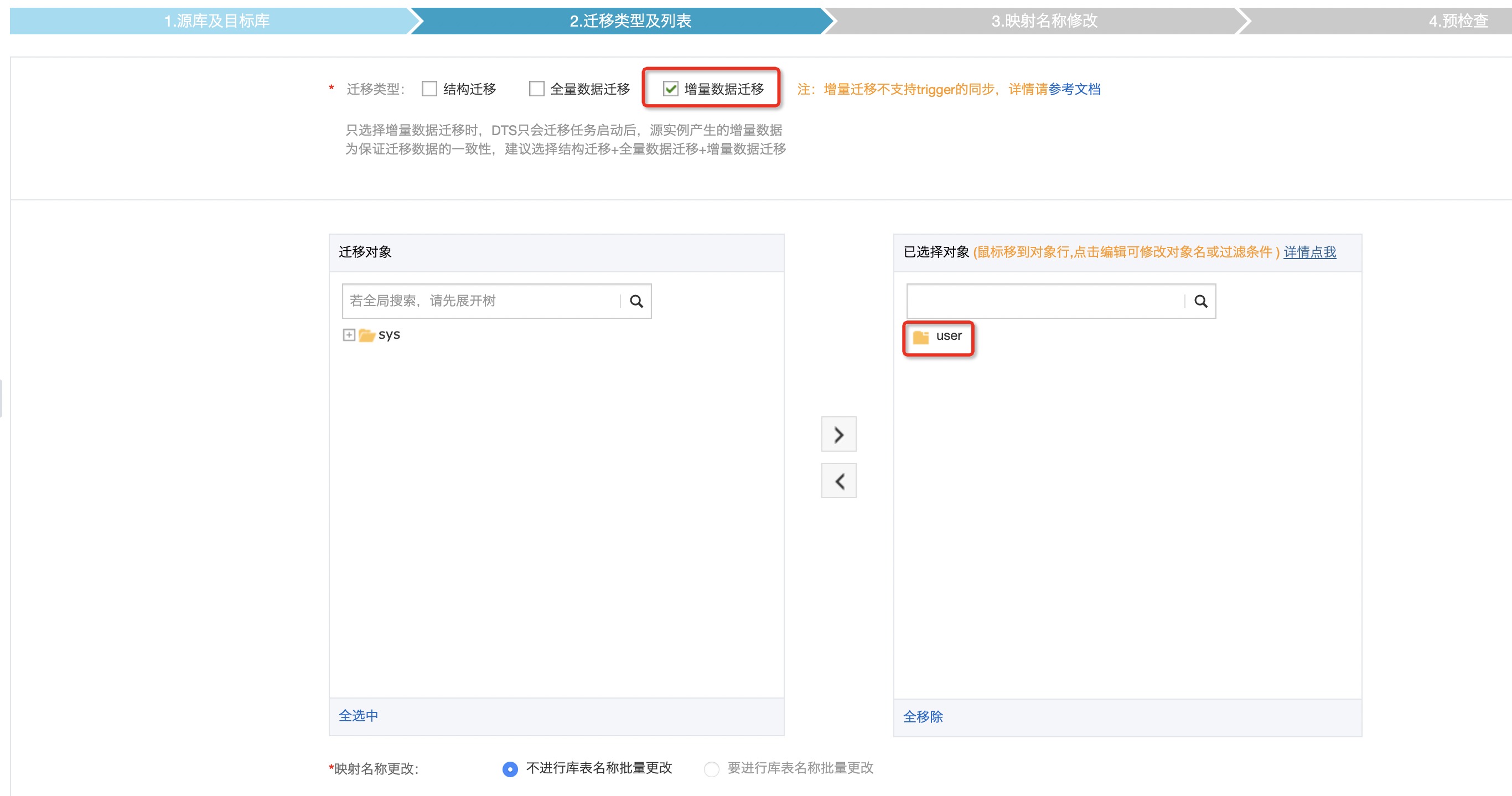
3、选择迁移类型和列表

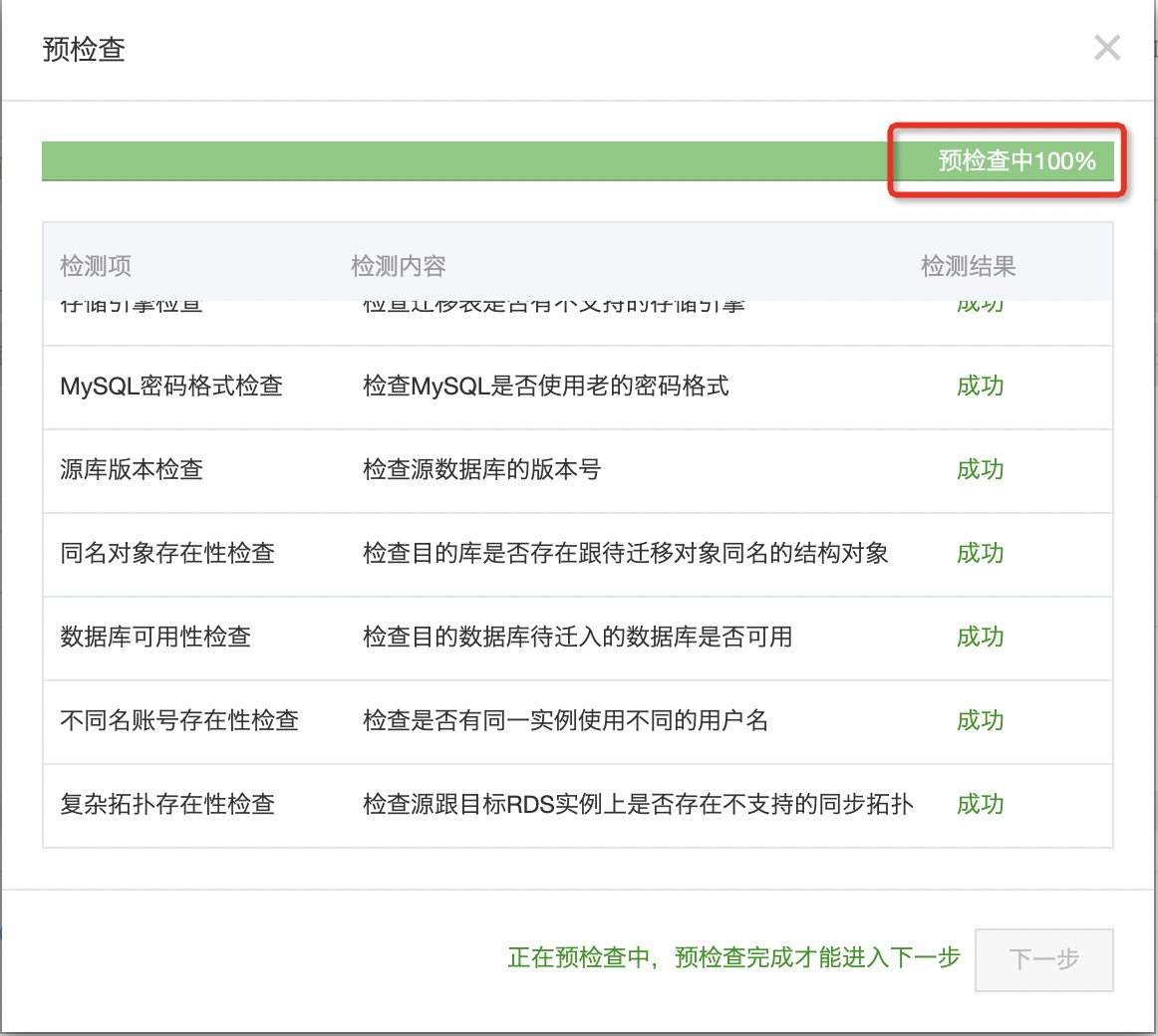
4、预检查
5、启动迁移任务
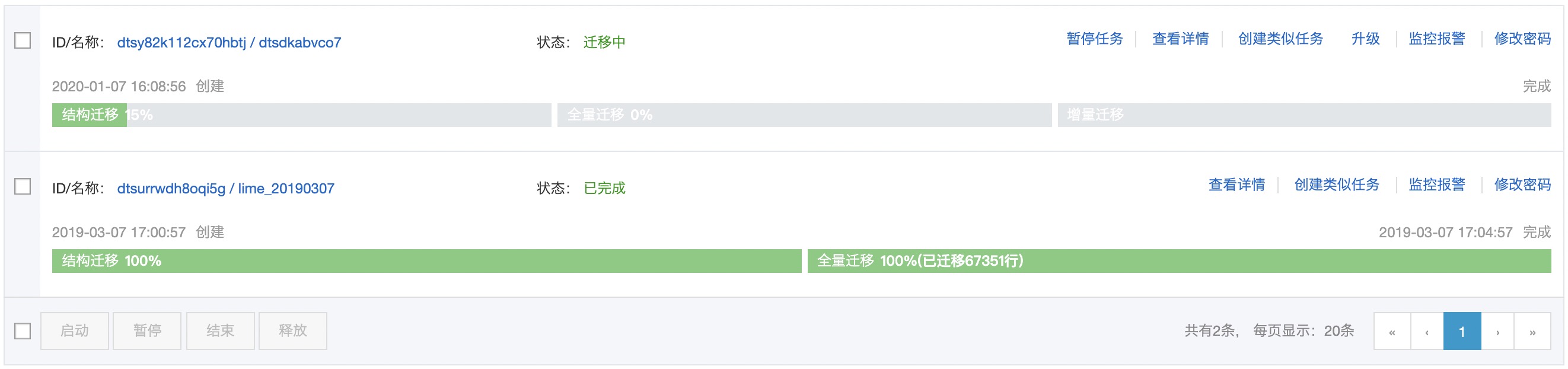
6、实时跟踪迁移进度
7、将业务中断,禁止新的数据写入源数据库
8、结束数据迁移任务
观察迁移任务的进度为增量迁移,并显示为无延迟状态时,将源库停写几分钟,等待迁移任务的增量迁移再次进入无延迟状态后,手动结束迁移任务。

9、创建反向数据迁移任务并启动
用于将目标库后续产生增量数据迁移回源数据库,此步骤创建的反向迁移任务的作用是为业务提供回退方案,业务恢复运行后,一旦出现异常可将业务切换至原有的数据库中。

⚠️ 警告:在配置反向数据迁移任务时,在设置迁移类型及列表环节仅需选择增量数据迁移。
阿里云 ECS 服务器
1 | # 登陆账户:工号 + 密码 |
本地 IDC 服务器
1 | ssh -p 2222 01510886@10.138.16.192 |
使用 :s 命令可以实现字符串的替换
1 | # 用字符串 str2 替换行中首次出现的字符串 str1 |
1 | #!/bin/bash |
1 | your_name="test" |
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数 |
| $$ | 脚本运行的当前进程 ID 号 |
| $! | 后台运行的最后一个进程的 ID 号 |
| $@ | 以 “$n” 的形式输出所有参数 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
1 | $* 与 $@ 区别: |
1 | # 获取数组所有元素 |
| 数字运算符 | 说明 |
|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 |
| 字符串运算符 | 说明 |
|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 |
| != | 检测两个字符串是否相等,不相等返回 true。 |
| -z | 检测字符串长度是否为 0,为 0 返回 true。 |
| -n | 检测字符串长度是否不为 0,不为 0 返回 true。 |
| $ | 检测字符串是否为空,不为空返回 true。 |
| 逻辑运算符 | 说明 |
|---|---|
| && | 逻辑的 AND |
| || | 逻辑的 OR |
| 文件运算符 | 说明 |
|---|---|
| -d file | 检测文件是否是目录,如果是,则返回 true。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于 0),不为空返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 |
1 | # if else |
1 | [ function ] funname [()] |
| 命令 | 说明 |
|---|---|
| command > file | 将输出重定向到 file |
| command < file | 将输入重定向到 file |
| command >> file | 将输出以追加的方式重定向到 file |
| n > file | 将文件描述符为 n 的文件重定向到 file |
| n >> file | 将文件描述符为 n 的文件以追加的方式重定向到 file |
| n >& m | 将输出文件 m 和 n 合并 |
| n <& m | 将输入文件 m 和 n 合并 |
| << tag | 将开始标记 tag 和结束标记 tag 之间的内容作为输入 |
注意:文件描述符 0 通常是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)
1 | # 将 stdout 和 stderr 合并后重定向到 file |
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null。
北京亦庄机房,MySQL 数据库服务器
主:10.159.39.238
从:10.159.39.239
1 | rename table xx to xx_bak; |
1 | lock tables haier_user_clientsso_log read; |