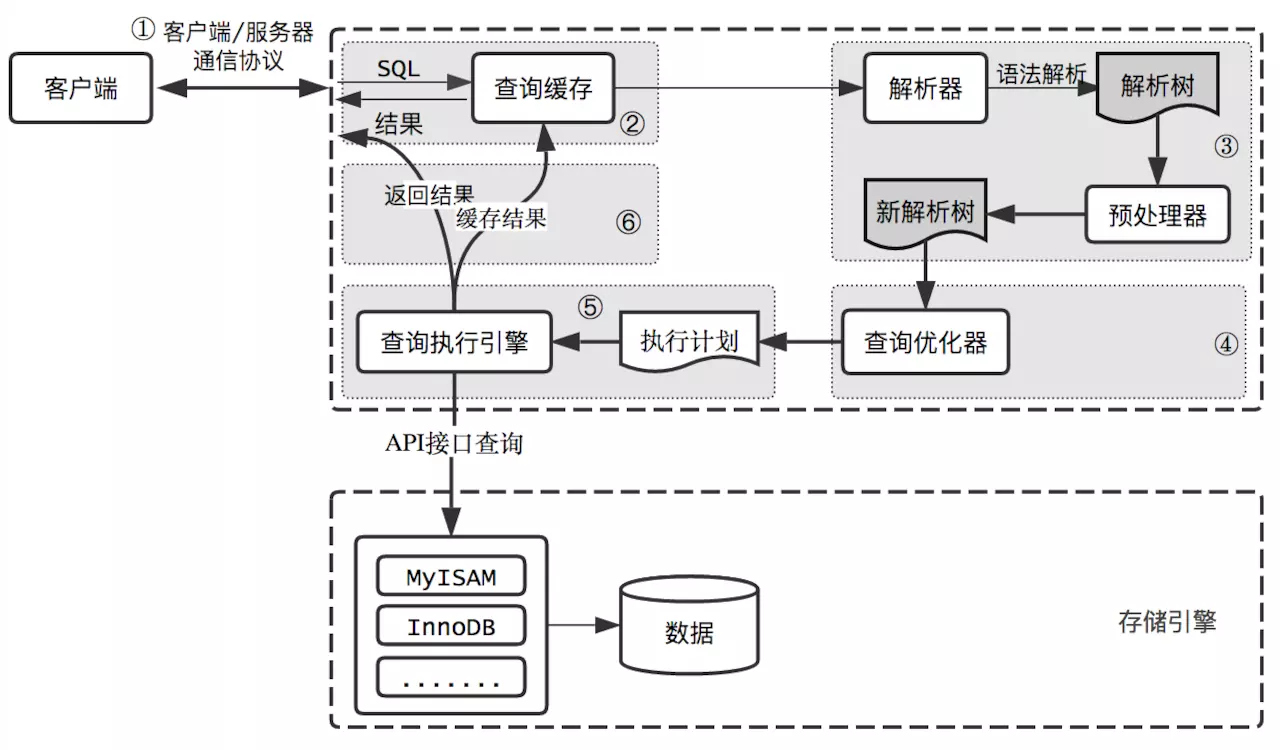
背景
| 项目信息 | 说明 |
|---|---|
| 项目名称 | 售后服务微信公众号 |
| 机房位置 | 北京亦庄 / 卓朗机房 |
| 本地数据库 | 10.199.96.188 |
| 数据量 | 140 GB |
| 版本 | MySQL 5.5 |
| 阿里云 ECS | 说明 |
|---|---|
| 主机 | 47.95.110.25 |
| 自建 MySQL | MySQL 5.5 |
| 用户名 | root |
| 密码 | HkdV*Q4mVavjYRSg |
| 阿里云 RDS | 说明 |
|---|---|
| 实例 | rm-2zeh0aso72hr897it.mysql.rds.aliyuncs.com:3306 |
| 版本 | MySQL 5.6 |
| 用户名 | haierfw |
| 密码 | ** |
迁移方案
本地 IDC 数据库 -> ECS 自建数据库 -> 阿里云 RDS
操作
| 步骤 | 耗时 |
|---|---|
| 全备 | 30 min |
| 传输 | 3 h 30 min |
| 增备 | 30 min |
| 恢复 | 30 min |
| DTS 迁移 | 2 h 30 min |
实施
- 全量备份
1 | innobackupex --defaults-file=/etc/my.cnf --user=sre --password='xx' --no-timestamp /data/backup |
- 传输
1 | scp -r /data/backup/* root@47.95.110.25:/data/backup |
- 全量恢复
1 | mysqladmin -uroot -p'xx' shutdown |
- 增量备份
在进行增量备份时,首先要进行一次全量备份,第一次增量备份是基于全备的,之后的增量备份是基于上一次的增量备份,以此类推。
1 | innobackupex --defaults-file=/etc/my.cnf --user=sre --password='xx' --incremental /data/incremental --incremental-basedir=/data/backup --parallel=2 |
- 增量恢复
1 | innobackupex --defaults-file=/etc/my.cnf --apply-log --redo-only /data/backup |
- 配置复制
1 | # 获取Master binlog位置 |
- 传输
1 | scp -r /data/backup/* root@47.95.110.25:/data/backup |